
At this point of the course, we have conclusively demonstrated that lots of languages are not regular, including palindromes, and strings with equal numbers of a’s and b’s, or strings containing correct addition statements. Since real-world digital computers are DFAs. We’ve convincingly proved that no computer can take an input string and tell us whether that string is a palindrome, or whether it has the same number of a’s and b’s, or whether it’s correct addition. Yet it certainly seems like we can write programs to solve these tasks. How can we resolve this contradiction?
There are two alternatives. First, we can admit that computability theory is right; there is no way we can write a correct program that works for all finite input strings!
For example, one way to check whether a string is a palindrome is to read it into memory, and then compare the characters working inwards from the ends. But if you are given a (finite!) input string that consists of fifty trillion trillion characters, no computer on earth can store the input in order to see if the first half and second half match! What computability theory is telling us is that there’s no clever workaround to store less information and recognize arbitrarily long palindromes using a finite amount of memory.
The other possible response to proving that most interesting problems cannot be solved using real-world computers is denial, which is a more rational response than it sounds.
After all, the only reason a computer/DFA can’t recognize palindromes is that it might run out of memory for sufficiently long inputs. But in practice we usually have enough memory to handle the inputs we care about.
So perhaps it makes more sense to consider models of computation that are not limited to a fixed amount of memory? After all, there’s no difference in practice between having a large finite memory and having infinite memory - at least until we get too ambitious and run out of memory.
A Push-Down Automata (PDA) is the simplest extension of a NFA with extra (unlimited) memory. Specifically, a PDA is an NFA that has access to a stack, with no limit on how much the stack can hold.
Transitions now depend on the current state, the next input character, and the value we pop off the top of the stack. Further, when we take a transition not only do we change the state of the PDA, but we also have the option of pushing new data onto the stack. Finally, a PDA accepts a string if it ends up in an accepting/final state and the stack is empty.
Rather than jump straight to the formal definition of a PDA, we’ll look at some examples. And before we look at the examples, we need to discuss how PDA transitions work, compared to NFAs.
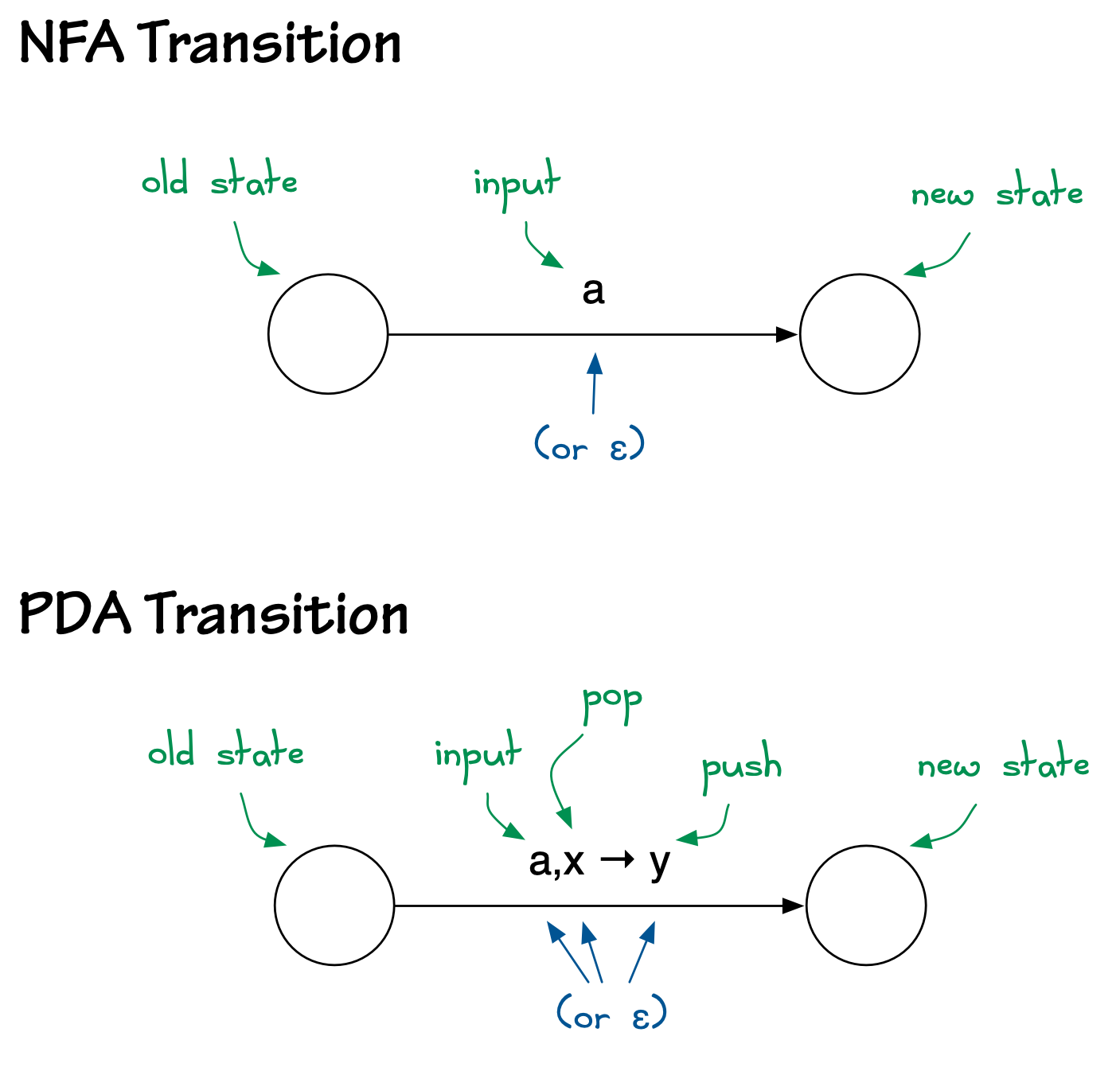
In an NFA, we can take the transition if the next input character is
the same as the label on the arrow, e.g., a. In a PDA, we
can take the transition only if we can read a certain input character
and if we can pop a certain stack character off the top of the
stack. If so, we push a new character on to the stack and update the
state.
Of course, like NFAs, a PDA can use \(\epsilon\) in transitions. In the case of a PDA, we can use \(\epsilon\) for the character to be read (meaning the transition reads no input), use \(\epsilon\) for the character to be popped from the stack (the transition pops nothing from the stack), and/or use \(\epsilon\) for the character to be pushed onto the stack (meaning the transition pushes nothing onto the stack).
Example
The following PDA accepts the language \[
\{\ 0^n1^n\ |\ n\geq 0\ \}. \] Since this is clearly a
non-regular language, it demonstrates that PDAs are more powerful than
NFAs (and DFAs). > > 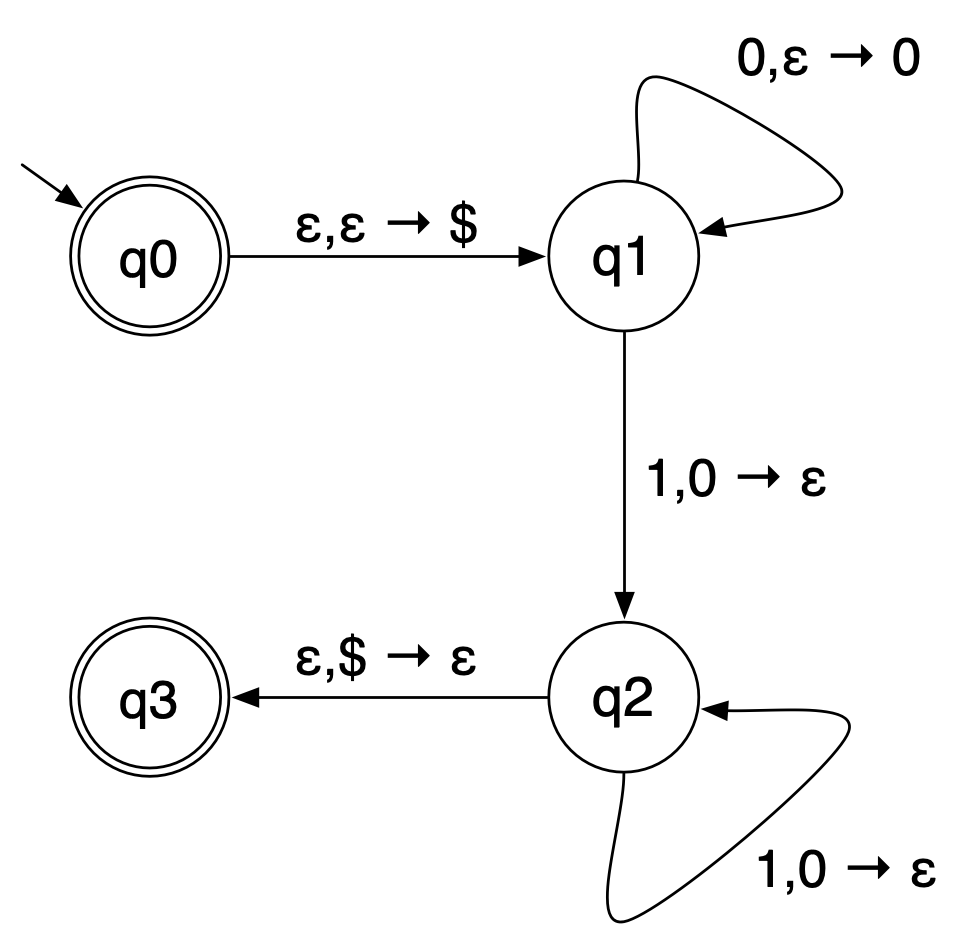 > > Intuitively, this PDA starts by pushing
the special symbol
> > Intuitively, this PDA starts by pushing
the special symbol $ onto the stack. (A PDA transition
can’t test for an empty stack, but if we push $ onto the
empty stack as soon as we start, and never push $ onto the
stack again, seeing $ on the top of the stack guarantees
there’s nothing else there.) > Then (in state q1) it reads 0’s from
the input and pushes them onto the stack. When it sees a 1, it switches
to reading 1’s and popping 0’s from the stack. If there were the same
number of 0’s as 1’s, then we will run out of input 1’s at the same time
we run out of stack 0’s. > If so, $ will be back on top
of the stack; we pop this off and switch to state q3, and the PDA
accepts (because the input is done, the stack is empty, and it’s in an
accept state).
Example
The following PDA accepts strings with the same number of a’s and
b’s. > 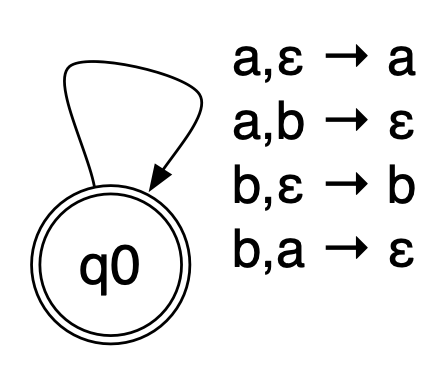 >
Intuitively, as the input is read, the PDA can use the stack to track
whether there have been more a’s than b’s so far (in which the stack
will contain exactly the excess a’s), or more b’s than a’s so far (in
which the stack will contain exactly the excess b’s). > If we read in
an a when there are b’s on the stack they can cancel (by popping the b)
and vice versa. Otherwise, we can just push the input a or input b onto
the stack. > Of course, there are other possible behaviours; the
automaton could read in a’s and b’s and never cancel, just pushing
everything on the stack. But in a nondeterministic machine like this, a
string is accepted if there is at least one series of legal
transitions that succeeds.
>
Intuitively, as the input is read, the PDA can use the stack to track
whether there have been more a’s than b’s so far (in which the stack
will contain exactly the excess a’s), or more b’s than a’s so far (in
which the stack will contain exactly the excess b’s). > If we read in
an a when there are b’s on the stack they can cancel (by popping the b)
and vice versa. Otherwise, we can just push the input a or input b onto
the stack. > Of course, there are other possible behaviours; the
automaton could read in a’s and b’s and never cancel, just pushing
everything on the stack. But in a nondeterministic machine like this, a
string is accepted if there is at least one series of legal
transitions that succeeds.
Definition
A Push-Down Automaton (PDA) is a 6-tuple \((Q, \Sigma, \Gamma, \delta, q_0, F)\) where > >- \(Q\) is a nonempty set (the states of the PDA) >- \(\Sigma\) is an alphabet. >- \(\Gamma\) is an alphabet of stack symbols. >- \(\delta : \bigl(Q \times (\Sigma\cup\{\epsilon\}) \times (\Gamma\cup\{\epsilon\})\bigr) \to {\cal P}(Q\times(\Gamma\cup\{\epsilon\}))\) is the nondeterministic transition function. >- \(q_0 \in Q\) is the start state. >- \(F \subseteq Q\) is the set of final (or accepting) states. > >\(\Sigma\) tells us what characters can appear in the input, while \(\Gamma\) tells us what symbols can be stored on the stack. The sets \(\Sigma\) and \(\Gamma\) could be the same, but they don’t have to be.
The formal languages where membership can be decided by a PDA are called Context-Free Languages (CFLs).
The examples above show that not every CFL is regular. However, every regular language is context-free; a PDA that ignores its stack (never pushing or popping any characters) is just an NFA, so any language that has an NFA also has a PDA.
That is, the collection of all context-free languages is a strict superset of the collection of all regular languages.
In Computer Science practice, however, there is another way to describe context-free languages that turns out to be more useful than PDAs, namely Context-Free Grammars (CFGs). We therefore turn to CFGs.
Previous: 6.9 Pumping Lemma
Next: 6.11 CFGs